|
|
| Line 103: |
Line 103: |
| | rack-mount server that implements the CP. | | rack-mount server that implements the CP. |
| | | | |
| − | === Datapath Software === | + | === Network Processor Software === |
| | + | |
| | + | |
| | + | [[Image:spp.npe|right|400px|Network Processor Blades]] |
| | + | NP blades are used for both the NPE and LC. |
| | | | |
| | === Control Software === | | === Control Software === |
| Line 119: |
Line 123: |
| | Keep the main flow at a high level, but add a page that gives a tutorial on | | Keep the main flow at a high level, but add a page that gives a tutorial on |
| | how the GEC 4 demo is done. | | how the GEC 4 demo is done. |
| − |
| |
| − | _____________________________________________________________
| |
| − |
| |
| − |
| |
| − |
| |
| − | Currently, overlay platforms are constructed using general purpose servers,
| |
| − | often organized into a cluster with a load-balancing switch acting as a
| |
| − | front end.
| |
| − | This project explores more integrated and scalable architectures suitable
| |
| − | for supporting large-scale applications with thousands to many millions of
| |
| − | end users.
| |
| − | In addition, we are studying various network level issues relating to the
| |
| − | control and management of large-scale overlay hosting services.
| |
| − |
| |
| − | == Overvew ==
| |
| − |
| |
| − | An ''Overlay Hosting Service'' (OHS) is a shared infrastructure that supports
| |
| − | multiple overlay networks. There are two major physical components to an OHS,
| |
| − | the ''Overlay Hosting Platforms'' (OHP) and the links joining OHPs to one another.
| |
| − | These links are expected to have provisioned bandwidth, allowing the OHS to
| |
| − | deliver provisioned capacity to the overlay networks that operate within it.
| |
| − | Access to the OHS infrastructure uses the Internet for the final hop.
| |
| − | This traffic can be carried over UDP tunnels, or virtual links,
| |
| − | depending on the deployment context (e.g. MPLS or VLAN).
| |
| − |
| |
| − | [[Image:ohs.gif|frame|right|Overlay Hosting Service]]
| |
| − |
| |
| − | The OHPs contain flexible processing resources that can be allocated to
| |
| − | different overlays. The resources allocated to an overlay node can range from
| |
| − | a small fraction of a general-purpose server, up to hundreds
| |
| − | of high performance multi-core processor subsystems.
| |
| − | To enable a wide range of overlay network architectures and service models,
| |
| − | it's important for OHSs to be as flexible as possible.
| |
| − | Overlay network providers should be free to define their own
| |
| − | protocols, packet formats and service models, within the framework provided by the OHS.
| |
| − |
| |
| − | The use of provisioned links between OHPs allows OHS providers to deliver provisioned
| |
| − | overlay links to the overlay providers, making it possible for overlay networks
| |
| − | to provide consistent performance to their users. For access over UDP tunnels,
| |
| − | true QoS may be difficult to achieve, but even here there is the potential for
| |
| − | significantly better performance than can be achieved over end-to-end connections
| |
| − | in the public Internet.
| |
| − |
| |
| − | To clarify the role of various elements of an OHS, it's helpful to introduce some terminology.
| |
| − | The infrastructure and core services provided by the OHS are referred to as the
| |
| − | ''substrate''. We also use substrate to refer to the core services provided by
| |
| − | the OHPs. We use ''overlay'' to refer to each overlay network hosted by an OHS,
| |
| − | and we use the term ''overlay node'' to refer to the individual nodes within the
| |
| − | overlay network. For brevity, we sometimes use ''platform'' in place of overlay
| |
| − | hosting platform, and ''node'' in place of overlay node.
| |
| − |
| |
| − | == Design Principles ==
| |
| − |
| |
| − | We start by articulating some core design principles to provide a framework
| |
| − | in which to consider more detailed design issues.
| |
| − |
| |
| − | === Architectural Neutrality ===
| |
| − |
| |
| − | The architectural neutrality principle states that the OHS should be neutral
| |
| − | with respect to the architectures and service models implemented by the overlays.
| |
| − | The motivation behind this is that we want to support the widest possible range
| |
| − | of overlay services, and to encourage innovation and creativity in the design
| |
| − | of new overlays. A successful OHS may operate for a period of many years,
| |
| − | making it likely that future overlays will have requirements that are very
| |
| − | different from those of current overlays.
| |
| − |
| |
| − | One important consequence of the architectural neutrality principle is that
| |
| − | the substrate should provide only the most essential services.
| |
| − | Because the substrate provides common elements used by all overlays,
| |
| − | any capability provided by the substrate is likely to become difficult
| |
| − | to change in the future. Consequently, any capability that we are likely to
| |
| − | want to change in the future, is best implemented in overlays rather than
| |
| − | in the substrate.
| |
| − |
| |
| − | === Resource Provisioning Model ===
| |
| − |
| |
| − | There are two very different approaches that one can take to providing a
| |
| − | flexible overlay hosting capability. The ''resource provisioning'' approach seeks
| |
| − | to make resources available, without imposing any specific usage model on
| |
| − | those resources. In this approach, there may be a variety of different resources
| |
| − | provided for use by overlays, and the specific kinds of resources can change over time.
| |
| − |
| |
| − | The alternative ''abstract programming interface'' approach attempts to shield overlay
| |
| − | overlay developers from the characteristics of the underlying hardware
| |
| − | components, by providing a system level abstraction through which users
| |
| − | can implement new functionality. This has some obvious appeal, since it can
| |
| − | allow developers to work at a higher level of abstraction, and to readily port their overlay
| |
| − | network functionality to take advantage of new hardware subsystems, without
| |
| − | a major new development effort.
| |
| − |
| |
| − | In deference to the architectural neutrality principle, we favor the resource
| |
| − | provisioning approach. However, it is important to recognize that this does
| |
| − | not rule out higher level development processes for overlays. It just separates
| |
| − | the provision of higher level APIs from the OHS substrate. One can certainly
| |
| − | envision higher level programming environments that target specific resources
| |
| − | that may be available within an OHS. While the introduction of new hardware
| |
| − | resources may require the development of new code generators for compilers,
| |
| − | and/or runtime environments, developers of overlay networks can still be
| |
| − | insulated from the idiosyncrasies of specific hardware configurations,
| |
| − | to a large degree.
| |
| − |
| |
| − | === Provisioned Resource Model ===
| |
| − |
| |
| − | Overlay hosting services support provisioned resources, allowing overlays to
| |
| − | reserve both link bandwidth and processing resources in hosting platforms.
| |
| − | This is necessary to enable overlays to engineer their services to provide
| |
| − | satisfactory performance to their users. While it will often not be possible
| |
| − | to provide provisioned bandwidth on access links connecting users to their
| |
| − | first-hop OHP, provisioned bandwidth should generally be available on
| |
| − | backbone links joining OHPs to one another.
| |
| − |
| |
| − | === Packet Based Communication ===
| |
| − |
| |
| − | Our interest is in overlay hosting services that support packet-based
| |
| − | communication, rather than circuits. While one can reasonably argue that
| |
| − | this is a violation of the architectural neutrality principle, we choose
| |
| − | to draw the line here. This choice does not rule out the provision of circuit-like
| |
| − | services, since these can be readily provided over a provisioned packet channel.
| |
| − | However, we do not support transparent access to underlying circuit services
| |
| − | (although the substrate may certainly use such services to provide packet
| |
| − | channels to overlays).
| |
| − |
| |
| − | === Technology Adaptability ===
| |
| − |
| |
| − | Since a successful OHS can be expected to last for many years or decades,
| |
| − | it's important that it be able to easily accommodate new types of processing
| |
| − | and transmission resources. We anticipate a wide range of processing resources,
| |
| − | including general purpose processors running conventional operating systems,
| |
| − | Network Processor subsystems with minimal run-time support and FPGA subsystems
| |
| − | that are configured strictly by overlay providers. As new resource types are
| |
| − | developed, it should be possible to incorporate them into the OHS infrastructure
| |
| − | without disrupting ongoing operations.
| |
| − |
| |
| − | ----
| |
| − |
| |
| − | The pages listed below provide more detailed discussion of specific issues
| |
| − | relating to internet-scale overlay hosting.
| |
| − |
| |
| − | * [[Scalable Overlay Hosting Platforms|Scalable Overlay Hosting Platforms]]
| |
| − | * [[Supercharged PlanetLab Platform|Supercharged PlanetLab Platform]]
| |
| − |
| |
| − | ----
| |
| − |
| |
| − | == References ==
| |
| − |
| |
| − | ;[BA06]:Bavier, A., N. Feamster, M. Huang, L. Peterson, J. Rexford. “In VINI Veritas: Realistic and Controlled Network Experimentation,” ''Proc. of ACM SIGCOMM'', 2006.
| |
| − |
| |
| − | ;[BH06]:Bharambe, A., J. Pang, S. Seshan. “Colyseus: A Distributed Archi-tecture for Online Multiplayer Games,” In ''Proc. Symposium on Networked Systems Design and Implementation'' (NSDI), 3/06.
| |
| − |
| |
| − | ;[CH02] :Choi, S., J. Dehart, R. Keller, F. Kuhns, J. Lockwood, P. Pappu, J. Parwatikar, W. D. Richard, E. Spitznagel, D. Taylor, J. Turner and K. Wong. “Design of a High Performance Dynamically Extensible Router.” In Proceedings of the DARPA Active Networks Conference and Exposition, 5/02.
| |
| − |
| |
| − | ;[CH03] :Chun, B., D. Culler, T. Roscoe, A. Bavier, L. Peterson, M. Wawr-zoniak, and M. Bowman. “PlanetLab: An Overlay Testbed for Broad-Coverage Services,” ACM Computer Communications Review, vol. 33, no. 3, 7/03.
| |
| − |
| |
| − | ;[CI06] :Cisco Carrier Routing System. At www.cisco.com/en/ US/products/ps5763/, 2006
| |
| − |
| |
| − | ;[DI02] :Dilley, J., B. Maggs, J. Parikh, H. Prokop, R. Sitaraman, and B. Weihl. “Globally Distributed Content Delivery,” IEEE Internet Computing, September/October 2002, pp. 50-58.
| |
| − |
| |
| − | ;[FO07] :Force 10 Networks. “S2410 Data Center Switch,” http:// www.force10networks.com/products/s2410.asp, 2007.
| |
| − |
| |
| − | ;[FR04] :Freedman, M., E. Freudenthal and D. Mazières. “Democratizing Content Publication with Coral,” In Proc. 1st USENIX/ACM Sym-posium on Networked Systems Design and Implementation, 3/04.
| |
| − |
| |
| − | ;[GE06] :Global Environment for Network Innovations. http://www.geni.net/, 2006.
| |
| − |
| |
| − | ;[HI98] :Mike Hicks_ Pankaj Kakkar_ Jonathan T_ Moore_ Carl A_ Gunter_ and Scott Nettles. “PLAN, A packet language for active networks,” In Proceedings of the Third ACM SIGPLAN International Conference on Functional Programming Languages, 1998.
| |
| − |
| |
| − | ;[IXP] :Intel IXP 2xxx Product Line of Network Processors. http://www.intel.com/design/network/products/npfamily/ixp2xxx.htm.
| |
| − |
| |
| − | ;[KA02] :Karlin, Scott and Larry Peterson. “VERA: An Extensible Router Architecture,” In Computer Networks, 2002.
| |
| − |
| |
| − | ;[KO00] :Kohler, Eddie, Robert Morris, Benjie Chen, John Jannotti and M. Frans Kaashoek. “The Click modular router,” ACM Transactions on Computer Systems, 8/2000.
| |
| − |
| |
| − | ;[KO04] :Kontothanassis, L. R. Sitaraman, J. Wein, D. Hong, R. Kleinberg, B. Mancuso, D. Shaw and D. Stodolsky. “A Transport Layer for Live Streaming in a Content Delivery Network,” Proc. of the IEEE, Special Issue on Evolution of Internet Technologies, 9/04.
| |
| − |
| |
| − | ;[PA03] :Pappu, P., J. Parwatikar, J. Turner and K. Wong. “Distributed Queueing in Scalable High Performance Routers.” Proceeding of IEEE Infocom, 4/03.
| |
| − |
| |
| − | ;[PE02] :Peterson, L., T. Anderson, D. Culler and T. Roscoe. “A Blueprint for Introducing Disruptive Technology into the Internet,” Proceed-ings of ACM HotNets-I Workshop, 10/02.
| |
| − |
| |
| − | ;[RA05] :Radisys Corporation. “Promentum™ ATCA-7010 Data Sheet,” product brief, available at http://www.radisys.com/files/ATCA-7010_07-1283-01_0505_datasheet.pdf.
| |
| − |
| |
| − | ;[RH05] :Rhea, S., B. Godfrey, B. Karp, J. Kubiatowicz, S. Ratnasamy, S. Shenker, I. Stoica and H. Yu. “OpenDHT: A Public DHT Service and Its Uses,” Proceedings of ACM SIGCOMM, 9/2005.
| |
| − |
| |
| − | ;[SP01] :Spalink, T., S. Karlin, L. Peterson and Y. Gottlieb. “Building a Robust Software-Based Router Using Network Processors,” In ACM Symposium on Operating System Principles (SOSP), 2001.
| |
| − |
| |
| − | ;[ST01] :Stoica, I., R. Morris, D. Karger, F. Kaashoek and H. Balakrishnan. “Chord: A scalable peer-to-peer lookup service for internet applica-tions.” In Proceedings of ACM SIGCOMM, 2001.
| |
| − |
| |
| − | ;[ST02] :Stoica, I., D. Adkins, S. Zhuang, S. Shenker, S. Surana, “Internet Indirection Infrastructure,” Proc. of ACM SIGCOMM, 8/02.
| |
| − |
| |
| − | ;[TU06] :Turner, J. “A Proposed Architecture for the GENI Backbone Plat-form,” In Proceedings of ACM- IEEE Symposium on Architectures for Networking and Communications Systems (ANCS), 12/2006.
| |
| − |
| |
| − | ;[VS06]:Linux vServer. http://linux-vserver.org
| |
Currently under reconstruction - check back later
Network overlays have become a popular tool for implementing Internet applications.
While content-delivery networks provide the most prominent example of the commercial application
of overlays, systems researchers have developed a variety of experimental
overlay applications, demonstrating that the overlay approach can be an effective method
for deploying a broad range of innovative systems. An Overlay hosting Service (OHS)
is a shared infrastructure that supports multiple overlay networks and
can play an important role in enabling wider-scale use of overlays,
since it enables small organizations to deploy new overlay services on a global scale
without the burden of having to acquire and manage their own physical infrastructure.
Currently, PlanetLab is the canonical example of an overlay hosting service, and it has
proven to be an effective vehicle for supporting research in distributed systems
and applications. This project seeks to make PlanetLab and systems like it more
capable of supporting large-scale deployments of overlay services, through the
creation of more capable platforms and the control mechanisms needed to
provision resources for use by different applications.
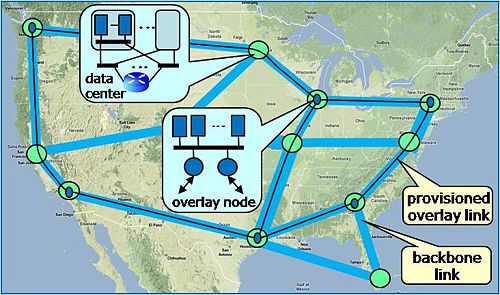
As shown at right, an OHS can be implemented using distributed data centers,
comprising servers and a communications substrate that includes both L2 switching
for local communication and L3 routers for communication to end users and other
data centers. End users communicate with a data center using the public Internet,
while data centers can communicate with each other, using either the public Internet
or dedicated backbone links, allowing the OHS to support provisioned overlay links.
This in turn allows overlay network providers to deliver services that require
consistent performance from the networking substrate.
We have developed an experimental prototype of a system for implementing overlay hosting services.
We have selected PlanetLab as our target implementation context and have
dubbed the system the Supercharged PlanetLab Platform.
The SPP has a scalable architecture that accommodates multiple types
of processing resources, including conventional server blades and Network Processor blades
base on the Intel IXP 2850.
We are working to deploy five SPP nodes in Internet 2 as part of a larger prototyping effort
associated with National Science Foundation's GENI initiative.
The subsequent sections describe the SPP and our plans for GENI.
Supercharged PlanetLab Platform
The SPP is designed as a high performance substitute for a conventional PlanetLab node.
The typical PlanetLab node is a conventional PC running a customized version of Linux
that supports multiple virtual machines, using the Linux vServer mechanism.
This allows different applications to share the node's computing and network resources,
while being logically isolated from the other applications running on the node.
PlanetLab's virtualization of the platform is imperfect, as it requires different
vServers to share a common IP address and because it provides limited support for
performance isolation. Nevertheless, PlanetLab has been very successful as an
experimental platform for distributed applications.
The objective of the SPP is to boost the performance of PlanetLab sufficiently to allow
it to serve as an effective platform for service delivery, not just for experimentation.
There are several elements to this. First, the SPP is designed as a scalable system that
incorporates multiple servers, while appearing to users and application developers like a conventional
PlanetLab node. Second, the SPP makes use of Network Processor blades, in addition to
conventional server blades, allowing developers to take advantage of the higher performance
offered by NPs. Third, the SPP provides better control over both computing and networking
resources, enabling developers to deliver more consistent performance to users.
PlanetLab developers can use the SPP just like a conventional PlanetLab node, but in order
to obtain the greatest performance benefits, they must structure their applications to
take advantage of the NP resources provided by the SPP. We have tried to make this relatively
painless, by supporting a simple fastpath/slowpath application structure, in which the NP
is used to implement the most performance-critical parts of an application, while the more
complex aspects of the application are handled by a general-purpose server that provides a
conventional software execution environment.
In this section, we provide an overview of the hardware and software components
that collectively implement the SPP, and describe how they can be used to implement
high performance PlanetLab applications.
Hardware Components
The hardware components of our prototype SPP are shown at right.
The system consists of a number of processing components that are connected by an
Ethernet switching layer. From a developer's perspective, the most important components
of the system are the Processing Engines that host the applications.
The SPP includes two types of PEs. The General-Purpose Processing Engines (GPE)
are conventional server blades running the standard PlanetLab operating system.
The current GPEs are dual Xeons with a clock rate of xx, xx GB of DRAM and xx GB of
on-board disk.
The Network Processor Blades (NPE) include two IXP 2850s, each with 16
cores for processing packets and an xScale management processor. Each IXP has
750 MB of RDRAM plus four independent SRAM banks, and the two share an 18 Mb TCAM.
The NPE also has a 10 GbE network connection and is capable of forwarding packets at 10 Gb/s.
All input and output passes through a Line Card (LC) that has ten GbE interfaces.
In a typical deployment, some of these interfaces will have public IP addresses and
be accessible through the Internet, while others will be used for direct connection
to other SPP nodes. The LC is implemented with a Network Processor blade and handles
the routing of traffic between the external interfaces and the GPEs and NPEs. This is
done by configuring filters and queues within the LC. The system is managed by a
Control Processor (CP) that configures application slices based on slice descriptions
obtained from PlanetLab Central, a centralized database that is used to manage the
global PlanetLab infrastructure. The CP also hosts a netFPGA, allowing application
developers to implement processing in configurable hardware, as well as software.
Our prototype system is shown in the photograph. We are using board level components
that are compatible with the Advanced Telecommunication Computing Architecture (ATCA)
standards. ATCA components include the server blades, the NP blades and the chassis
switch, which actually includes both a 10 GbE switch and a 1 GbE control switch.
The ATCA components are augmented with an external 1 GbE switch and a conventional
rack-mount server that implements the CP.
Network Processor Software
NP blades are used for both the NPE and LC.
Control Software
Planned SPP Deployment
map of planned node locations
details of a typical site with connections to router and other sites
Using SPPs
Discuss how to define slices in myPLC, login to SPP nodes and do configuration.
Keep the main flow at a high level, but add a page that gives a tutorial on
how the GEC 4 demo is done.

